-
Gap buffers are very easy to implement. A bare minimum implementation is about 60 lines of C.
-
Gap buffers are especially efficient for the majority of typical editing commands, which tend to be clustered in a small area.
-
Except for the gap, the content of the buffer is contiguous, making the search and display implementations simpler and more efficient. There’s also the potential for most of the gap buffer to be memory-mapped to the original file, though typical encoding and decoding operations prevent this from being realized.
-
Due to having contiguous content, saving a gap buffer is basically just two
write(2)system calls. (Plusfsync(2), etc.)
A gap buffer is really a pair of buffers where one buffer holds all of the content before the cursor (or point for Emacs), and the other buffer holds the content after the cursor. When the cursor is moved through the buffer, characters are copied from one buffer to the other. Inserts and deletes close to the gap are very efficient.
Typically it’s implemented as a single large buffer, with the pre-cursor content at the beginning, the post-cursor content at the end, and the gap spanning the middle. Here’s an illustration:

The top of the animation is the display of the text content and cursor as the user would see it. The bottom is the gap buffer state, where each character is represented as a gray block, and a literal gap for the cursor.
Ignoring for a moment more complicated concerns such as undo and Unicode, a gap buffer could be represented by something as simple as the following:
struct gapbuf {
char *buf;
size_t total; /* total size of buf */
size_t front; /* size of content before cursor */
size_t gap; /* size of the gap */
};
This is close to how Emacs represents it. In the structure above, the size of the content after the cursor isn’t tracked directly, but can be computed on the fly from the other three quantities. That is to say, this data structure is normalized.
As an optimization, the cursor could be tracked separately from the gap such that non-destructive cursor movement is essentially free. The difference between cursor and gap would only need to be reconciled for a destructive change — an insert or delete.
A gap buffer certainly isn’t the only way to do it. For example, the original vi used an array of lines, which sort of explains some of its quirky line-oriented idioms. The BSD clone of vi, nvi, uses an entire database to represent buffers. Vim uses a fairly complex rope-like data structure with page-oriented blocks, which may be stored out-of-order in its swap file.
Multiple cursors
Multiple cursors is fairly recent text editor invention that has gained a lot of popularity recent years. It seems every major editor either has the feature built in or a readily-available extension. I myself used Magnar Sveen’s well-polished package for several years. Though obviously the concept didn’t originate in Emacs or else it would have been called multiple points, which doesn’t quite roll off the tongue quite the same way.
The concept is simple: If the same operation needs to done in many different places in a buffer, you place a cursor at each position, then drive them all in parallel using the same commands. It’s super flashy and great for impressing all your friends.
However, as a result of improving my typing skills, I’ve come to the conclusion that multiple cursors is all hat and no cattle. It doesn’t compose well with other editing commands, it doesn’t scale up to large operations, and it’s got all sorts of flaky edge cases (off-screen cursors). Nearly anything you can do with multiple cursors, you can do better with old, well-established editing paradigms.
Somewhere around 99% of my multiple cursors usage was adding a common prefix to a contiguous serious of lines. As similar brute force options, Emacs already has rectangular editing, and Vim already has visual block mode.
The most sophisticated, flexible, and robust alternative is a good old macro. You can play it back anywhere it’s needed. You can zip it across a huge buffer. The only downside is that it’s less flashy and so you’ll get invited to a slightly smaller number of parties.
But if you don’t buy my arguments about multiple cursors being tasteless, there’s still a good technical argument: Gap buffers are not designed to work well in the face of multiple cursors!
For example, suppose we have a series of function calls and we’d like to add the same set of arguments to each. It’s a classic situation for a macro or for multiple cursors. Here’s the original code:
foo();
bar();
baz();
The example is tiny so that it will fit in the animations to come. Here’s the desired code:
foo(x, y);
bar(x, y);
baz(x, y);
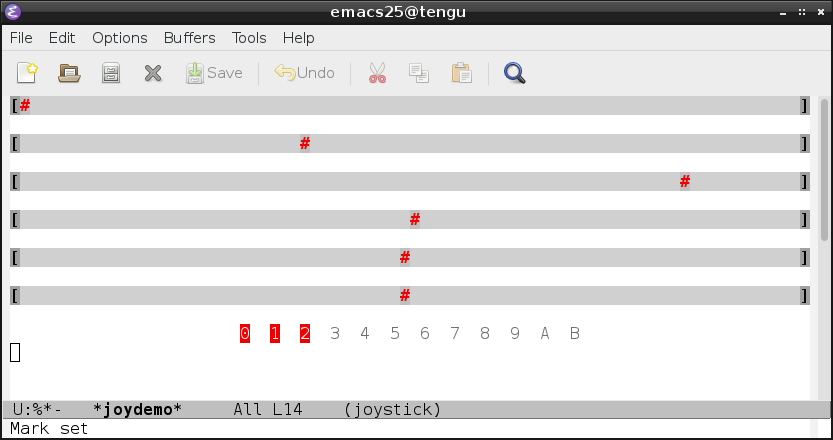
With multiple cursors you would place a cursor inside each set of
parenthesis, then type x, y. Visually it looks something like this:
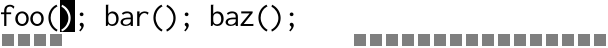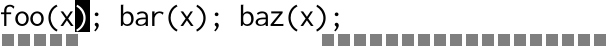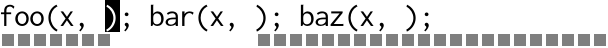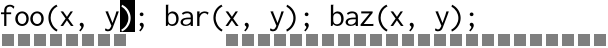
Text is magically inserted in parallel in multiple places at a time.
However, if this is a text editor that uses a gap buffer, the
situation underneath isn’t quite so magical. The entire edit doesn’t
happen at once. First the x is inserted in each location, then the
comma, and so on. The edits are not clustered so nicely.
From the gap buffer’s point of view, here’s what it looks like:
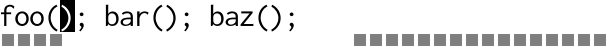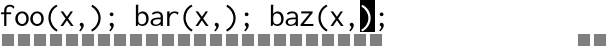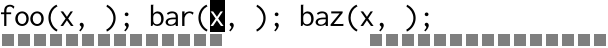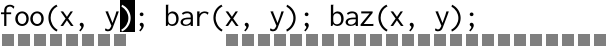
For every individual character insertion the buffer has to visit each
cursor in turn, performing lots of copying back and forth. The more
cursors there are, the worse it gets. For an edit of length n with
m cursors, that’s O(n * m) calls to memmove(3). Multiple cursors
scales badly.
Compare that to the old school hacker who can’t be bothered with something as tacky and modern (eww!) as multiple cursors, instead choosing to record a macro, then play it back:
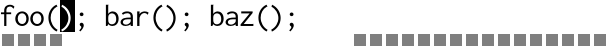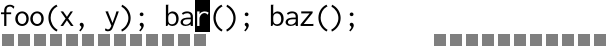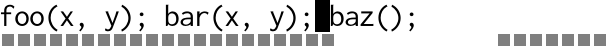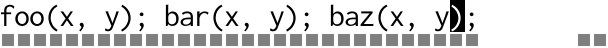
The entire edit is done locally before moving on to the next location.
It’s perfectly in tune with the gap buffer’s expectations, only needing
O(m) calls to memmove(3). Most of the work flows neatly into the
gap.
So, don’t waste your time with multiple cursors, especially if you’re using a gap buffer text editor. Instead get more comfortable with your editor’s macro feature. If your editor doesn’t have a good macro feature, get a new editor.
If you want to make your own gap buffer animations, here’s the source code. It includes a tiny gap buffer implementation:
]]>












 I was inspired by an item
in
I was inspired by an item
in 
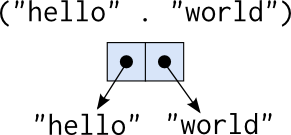
 However, if you're interested in digging into Common Lisp to try it
out, you may find yourself quickly running into walls just getting
started. It's a lot different than other programming environments you
may be used to. The Common Lisp tutorials generally skip this step,
assuming the user has an environment, or leaving that setup for the
"vendor" to handle. So, here's a guide to setting up a great Common
Lisp environment with
However, if you're interested in digging into Common Lisp to try it
out, you may find yourself quickly running into walls just getting
started. It's a lot different than other programming environments you
may be used to. The Common Lisp tutorials generally skip this step,
assuming the user has an environment, or leaving that setup for the
"vendor" to handle. So, here's a guide to setting up a great Common
Lisp environment with 