The source: dandelions.c
The game is played on a 5-by-5 grid where one player plays the dandelions, the other plays the wind. Players alternate, dandelions placing flowers and wind blowing in one of the eight directions, spreading seeds from all flowers along the direction of the wind. Each side gets seven moves, and the wind cannot blow in the same direction twice. The dandelions’ goal is to fill the grid with seeds, and the wind’s goal is to prevent this.
Try playing a few rounds with a friend, and you will probably find that dandelions is difficult, at least in your first games, as though it cannot be won. However, my engine proves the opposite: The dandelions always win with perfect play. In fact, it’s so lopsided that the dandelions’ first move is irrelevant. Every first move is winnable. If the dandelions blunder, typically wind has one narrow chance to seize control, after which wind probably wins with any (or almost any) move.
For reasons I’ll discuss later, I only solved the 5-by-5 game, and the situation may be different for the 6-by-6 variant. Also, unlike British Square, my engine does not exhaustively explore the entire game tree because it’s far too large. Instead it does a minimax search to the bottom of the tree and stops when it finds a branch where all leaves are wins for the current player. Because of this, it cannot maximize the outcome — winning as early as possible as dandelions or maximizing the number of empty grid spaces as wind. I also can’t quantify the exact size of tree.
Like with British Square, my game engine only has a crude user interface
for interactively exploring the game tree. While you can “play” it in a
sense, it’s not intended to be played. It also takes a few seconds to
initially explore the game tree, so wait for the >> prompt.
Bitboard seeding
I used bitboards of course: a 25-bit bitboard for flowers, a 25-bit bitboard for seeds, and an 8-bit set to track which directions the wind has blown. It’s especially well-suited for this game since seeds can be spread in parallel using bitwise operations. Shift the flower bitboard in the direction of the wind four times, ORing it into the seeds bitboard on each shift:
int wind;
uint32_t seeds, flowers;
flowers >>= wind; seeds |= flowers;
flowers >>= wind; seeds |= flowers;
flowers >>= wind; seeds |= flowers;
flowers >>= wind; seeds |= flowers;
Of course it’s a little more complicated than this. The flowers must be
masked to keep them from wrapping around the grid, and wind may require
shifting in the other direction. In order to “negative shift” I actually
use a rotation (notated with >>> below). Consider, to rotate an N-bit
integer left by R, one can right-rotate it by N-R — ex. on a 32-bit
integer, a left-rotate by 1 is the same as a right-rotate by 31. So for a
negative wind that goes in the other direction:
flowers >>> (wind & 31);
With such a “programmable shift” I can implement the bulk of the game rules using a couple of tables and no branches:
// clockwise, east is zero
static int8_t rot[] = {-1, -6, -5, -4, +1, +6, +5, +4};
static uint32_t mask[] = {
0x0f7bdef, 0x007bdef, 0x00fffff, 0x00f7bde,
0x1ef7bde, 0x1ef7bc0, 0x1ffffe0, 0x0f7bde0
};
f &= mask[dir]; f >>>= rot[i] & 31; s |= f;
f &= mask[dir]; f >>>= rot[i] & 31; s |= f;
f &= mask[dir]; f >>>= rot[i] & 31; s |= f;
f &= mask[dir]; f >>>= rot[i] & 31; s |= f;
The masks clear out the column/row about to be shifted “out” so that it doesn’t wrap around. Viewed in base-2, they’re 5-bit patterns repeated 5 times.
Bitboard packing and canonicalization
The entire game state is two 25-bit bitboards and an 8-bit set. That’s 58 bits, which fits in a 64-bit integer with bits to spare. How incredibly convenient! So I represent the game state using a 64-bit integer, using a packing like I did with British Square. The bottom 25 bits are the seeds, the next 25 bits are the flowers, and the next 8 is the wind set.
000000 WWWWWWWW FFFFFFFFFFFFFFFFFFFFFFFFF SSSSSSSSSSSSSSSSSSSSSSSSS
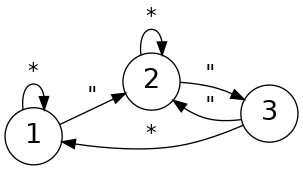
Even more convenient, I could reuse my bitboard canonicalization code from British Square, also a 5-by-5 grid packed in the same way, saving me the trouble of working out all the bit sieves. I only had to figure out how to transpose and flip the wind bitset. Turns out that’s pretty easy, too. Here’s how I represent the 8 wind directions:
567
4 0
321
Flipping this vertically I get:
321
4 0
567
Unroll these to show how old maps onto new:
old: 01234567
new: 07654321
The new is just the old rotated and reversed. Transposition is the same
story, just a different rotation. I use a small lookup table to reverse
the bits, and then an 8-bit rotation. (See revrot.)
To determine how many moves have been made, popcount the flower bitboard and wind bitset.
int moves = POPCOUNT64(g & 0x3fffffffe000000);
To test if dandelions have won:
int win = (g&0x1ffffff) == 0x1ffffff;
Since the plan is to store all the game states in a big hash table — an MSI double hash in this case — I’d like to reserve the zero value as a “null” board state. This lets me zero-initialize the hash table. To do this, I invert the wind bitset such that a 1 indicates the direction is still available. So the initial game state looks like this (in the real program this is accounted for in the previously-discussed turn popcount):
#define GAME_INIT ((uint64_t)255 << 50)
The remaining 6 bits can be used to cache information about the rest of tree under this game state, namely who wins from this position, and this serves as the “value” in the hash table. Turns out the bitboards are already noisy enough that a single xorshift makes for a great hash function. The hash table, including hash function, is under a dozen lines of code.
// Find the hash table slot for the given game state.
uint64_t *lookup(uint64_t *ht, uint64_t g)
{
uint64_t hash = g ^ g>>32;
size_t mask = (1L << HASHTAB_EXP) - 1;
size_t step = hash>>(64 - HASHTAB_EXP) | 1;
for (size_t i = hash;;) {
i = (i + step)&mask;
if (!ht[i] || ht[i]&0x3ffffffffffffff == g) {
return ht + i;
}
}
}
To explore a 6-by-6 grid I’d need to change my representation, which is part of why I didn’t do it. I can’t fit two 36-bit bitboards in a 64-bit integer, so I’d need to double my storage requirements, which are already strained.
Computational limitations
Due to the way seeds spread, game states resulting from different moves rarely converge back to a common state later in the tree, so the hash table isn’t doing much deduplication. Exhaustively exploring the entire game tree, even cutting it down to an 8th using canonicalization, requires substantial computing resources, more than I personally have available for this project. So I had to stop at the slightly weaker form, find a winning branch rather than maximizing a “score.”
I configure the program to allocate 2GiB for the hash table, but if you run just a few dozen games off the same table (same program instance), each exploring different parts of the game tree, you’ll exhaust this table. A 6-by-6 doubles the memory requirements just to represent the game, but it also slows the search and substantially increases the width of the tree, which grows 44% faster. I’m sure it can be done, but it’s just beyond the resources available to me.
Dandelion Puzzles
As a side effect, I wrote a small routine to randomly play out games in search for “mate-in-two”-style puzzles. The dandelions have two flowers to place and can force a win with two specific placements — and only those two placements — regardless of how the wind blows. Here are two of the better ones, each involving a small trick that I won’t give away here (note: arrowheads indicate directions wind can still blow):


There are a variety of potential single-player puzzles of this form.
- Cooperative: place a dandelion and pick the wind direction
- Avoidance: don’t seed a particular tile
- Hard ground: certain tiles can’t grow flowers (but still get seeded)
- Weeding: as wind, figure out which flower to remove before blowing
There could be a whole “crossword book” of such dandelion puzzles.
]]>













{kind=link}