nullprogram.com/blog/2021/12/04/
This article was discussed on Hacker News.
I recently learned of csvquote, a tool that encodes troublesome
CSV characters such that unix tools can correctly process them. It
reverses the encoding at the end of the pipeline, recovering the original
input. The original implementation handles CSV quotes using the
straightforward, naive method. However, there’s a better approach that is
not only simpler, but around 3x faster on modern hardware. Even more,
there’s yet another approach using SIMD intrinsics, plus some bit
twiddling tricks, which increases the processing speed by an order of
magnitude. My csvquote implementation includes both
approaches.
Background
Records in CSV data are separated by line feeds, and fields are separated
by commas. Fields may be quoted.
aaa,bbb,ccc
xxx,"yyy",zzz
Fields containing a line feed (U+000A), quotation mark (U+0022), or comma
(U+002C), must be quoted, otherwise they would be ambiguous with the CSV
formatting itself. Quoted quotation marks are turned into a pair of
quotes. For example, here are two records with two fields apiece:
"George Herman ""Babe"" Ruth","1919–1921, 1923, 1926"
"Frankenstein;
or, The Modern Prometheus",Mary Shelley
A CSV-unaware tool splitting on commas and line feeds (ex. awk) would
process these records improperly. So csvquote translates quoted line feeds
into record separators (U+001E) and commas into unit separators (U+001F).
These control characters rarely appear in normal text data, and can be
trivially processed in UTF-8-encoded text without decoding or encoding.
The above records become:
"George Herman ""Babe"" Ruth","1919–1921\x1f 1923\x1f 1926"
"Frankenstein;\x1eor\x1f The Modern Prometheus",Mary Shelley
I’ve used \x1e and \x1f here to illustrate the control characters.
The data is exactly the same length since it’s a straight byte-for-byte
replacement. Quotes are left entirely untouched. The challenge is parsing
the quotes to track whether the two special characters fall inside or
outside pairs of quotes.
State machine improvements
The original csvquote walks the input a byte at a time and is in one of
three states:
- Outside quotes (initial state)
- Inside quotes
- On a possibly “escaped” quote (the first
" in a "")
Since I love state machines so much, here it is translated into a
switch-based state machine:
// Return the next state given an input character.
int next(int state, int c)
{
switch (state) {
case 1: return c == '"' ? 2 : 1;
case 2: return c == '"' ? 3 : 2;
case 3: return c == '"' ? 2 : 1;
}
}
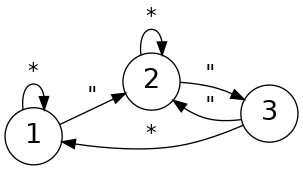
The real program also has more conditions for potentially making a
replacement. It’s an awful lot of performance-killing branching.
However, this context is about finding “in” and “out” — not validating
the CSV — so the “escape” state is unnecessary. I need only match up pairs
of quotes. An “escaped” quote can be considered terminating a quoted
region and immediately starting a new quoted region. That’s means there’s
just the first two states in a trivial arrangement:
int next(int state, int c)
{
switch (state) {
case 1: return c == '"' ? 2 : 1;
case 2: return c == '"' ? 1 : 2;
}
}
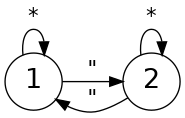
Since the text can be processed as bytes, there are only 256 possible
inputs. With 2 states and 256 inputs, this state machine, with
replacement machinery, can be implemented with a 512-byte table and no
branches. Here’s the table initialization:
unsigned char table[2][256];
void init(void)
{
for (int i = 0; i < 256; i++) {
table[0][i] = i;
table[1][i] = i;
}
table[1]['\n'] = 0x1e;
table[1][','] = 0x1f;
}
In the first state, characters map onto themselves. In the second state,
characters map onto their replacements. This is the entire encoder and
decoder:
void encode(unsigned char *buf, size_t len)
{
int state = 0;
for (size_t i = 0; i < len; i++) {
state ^= (buf[i] == '"');
buf[i] = table[state][buf[i]];
}
}
Well, strictly speaking, the decoder need not process quotes. By my
benchmark (csvdump in my implementation) this processes at ~1 GiB/s on
my laptop — 3x faster than the original. However, there’s still
low-hanging fruit to be picked!
SIMD and two’s complement
Any decent SIMD implementation is going to make use of masking. Find the
quotes, compute a mask over quoted regions, compute another mask for
replacement matches, combine the masks, then use that mask to blend the
input with the replacements. Roughly:
quotes = find_quoted_regions(input)
linefeeds = input == '\n'
commas = input == ','
output = blend(input, '\n', quotes & linefeeds)
output = blend(output, ',', quotes & commas)
The hard part is computing the quote mask, and also somehow handle quoted
regions straddling SIMD chunks (not pictured), and do all that without
resorting to slow byte-at-time operations. Fortunately there are some
bitwise tricks that can resolve each issue.
Imagine I load 32 bytes into a SIMD register (e.g. AVX2), and I compute a
32-bit mask where each bit corresponds to one byte. If that byte contains
a quote, the corresponding bit is set.
"George Herman ""Babe"" Ruth","1
10000000000000011000011000001010
That last/lowest 1 corresponds to the beginning of a quoted region. For my
mask, I’d like to set all bits following that bit. I can do this by
subtracting 1.
"George Herman ""Babe"" Ruth","1
10000000000000011000011000001001
Using the Kernighan technique I can also remove this bit from the
original input by ANDing them together.
"George Herman ""Babe"" Ruth","1
10000000000000011000011000001000
Now I’m left with a new bottom bit. If I repeat this, I build up layers of
masks, one for each input quote.
10000000000000011000011000001001
10000000000000011000011000000111
10000000000000011000010111111111
10000000000000011000001111111111
10000000000000010111111111111111
10000000000000001111111111111111
01111111111111111111111111111111
Remember how I use XOR in the state machine above to toggle between
states? If I XOR all these together, I toggle the quotes on and off,
building up quoted regions:
"George Herman ""Babe"" Ruth","1
01111111111111100111100111110001
However, for reasons I’ll explain shortly, it’s critical that the opening
quote is included in this mask. If I XOR the pre-subtracted value with the
mask when I compute the mask, I can toggle the remaining quotes on and off
such that the opening quotes are included. Here’s my function:
uint32_t find_quoted_regions(uint32_t x)
{
uint32_t r = 0;
while (x) {
r ^= x;
r ^= x - 1;
x &= x - 1;
}
return r;
}
Which gives me exactly what I want:
"George Herman ""Babe"" Ruth","1
11111111111111101111101111110011
It’s important that the opening quote is included because it means a
region that begins on the last byte will have that last bit set. I can use
that last bit to determine if the next chunk begins in a quoted state. If
a region begins in a quoted state, I need only NOT the whole result to
reverse the quoted regions.
How can I “sign extend” a 1 into all bits set, or do nothing for zero?
Negate it!
uint32_t carry = -(prev & 1);
uint32_t quotes = find_quoted_regions(input) ^ carry;
// ...
prev = quotes;
That takes care of computing quoted regions and chaining them between
chunks. The loop will unfortunately cause branch prediction penalties if
the input has lots of quotes, but I couldn’t find a way around this.
However, I’ve made a serious mistake. I’m using _mm256_movemask_epi8 and
it puts the first byte in the lowest bit. Doh! That means it looks like
this:
1","htuR ""ebaB"" namreH egroeG"
01010000011000011000000000000001
There’s no efficient way to flip the bits around, so I just need to find a
way to work in the other direction. To flip the bits to the left of a set
bit, negate it.
00000000000000000000000010000000 = +0x00000080
11111111111111111111111110000000 = -0x00000080
Unlike before, this keeps the original bit set, so I need to XOR the
original value into the input to flip the quotes. This is as simple as
initializing to the input rather than zero. The new loop:
uint32_t find_quoted_regions(uint32_t x)
{
uint32_t r = x;
while (x) {
r ^= -x ^ x;
x &= x - 1;
}
return r;
}
The result:
1","htuR ""ebaB"" namreH egroeG"
11001111110111110111111111111111
The carry now depends on the high bit rather than the low bit:
uint32_t carry = -(prev >> 31);
Reversing movemask
The next problem: for reasons I don’t understand, AVX2 does not include
the inverse of _mm256_movemask_epi8. Converting the bit-mask back into a
byte-mask requires some clever shuffling. Fortunately I’m not the first
to have this problem, and so I didn’t have to figure it out from
scratch.
First fill the 32-byte register with repeated copies of the 32-bit mask.
abcdabcdabcdabcdabcdabcdabcdabcd
Shuffle the bytes so that the first 8 register bytes have the same copy of
the first bit-mask byte, etc.
aaaaaaaabbbbbbbbccccccccdddddddd
In byte 0, I care only about bit 0, in byte 1 I care only about the bit 1,
… in byte N I care only about bit N%8. I can pre-compute a mask to
isolate each of these bits and produce a proper byte-wise mask from the
bit-mask. Fortunately all this isn’t too bad: four instructions instead of
the one I had wanted. It looks like a lot of code, but it’s really only a
few instructions.
Results
In my benchmark, which includes randomly occurring quoted fields, the SIMD
version processes at ~4 GiB/s — 10x faster than the original. I haven’t
profiled, but I expect mispredictions on the bit-mask loop are the main
obstacle preventing the hypothetical 32x speedup.
My version also optionally rejects inputs containing the two special
control characters since the encoding would be irreversible. This is
implemented in SIMD when available, and it slows processing by around 10%.
Followup: PCLMULQDQ
Geoff Langdale and others have graciously pointed out PCLMULQDQ,
which can compute the quote masks using carryless multiplication
(also) entirely in SIMD and without a loop. I haven’t yet quite
worked out exactly how to apply it, but it should be much faster.