nullprogram.com/blog/2015/11/21/
I recently released an Emacs package called x86-lookup.
Given a mnemonic, Emacs will open up a local copy of an Intel’s
software developer manual PDF at the page documenting the
instruction. It complements nasm-mode, released earlier this
year.
x86-lookup is also available from MELPA.
To use it, you’ll need Poppler’s pdftotext command line
program — used to build an index of the PDF — and a copy of the
complete Volume 2 of Intel’s instruction set manual. There’s only one
command to worry about: M-x x86-lookup.
Minimize documentation friction
This package should be familiar to anyone who’s used
javadoc-lookup, one of my older packages. It has a common
underlying itch: the context switch to read API documentation while
coding should have as little friction as possible, otherwise I’m
discouraged from doing it. In an ideal world I wouldn’t ever need to
check documentation because it’s already in my head. By visiting
documentation frequently with ease, it’s going to become familiar that
much faster and I’ll be reaching for it less and less, approaching the
ideal.
I picked up x86 assembly [about a year ago][x86] and for the first few
months I struggled to find a good online reference for the instruction
set. There are little scraps here and there, but not much of
substance. The big exception is Félix Cloutier’s reference,
which is an amazingly well-done HTML conversion of Intel’s PDF
manuals. Unfortunately I could never get it working locally to
generate my own. There’s also the X86 Opcode and Instruction
Reference, but it’s more for machines than humans.
Besides, I often work without an Internet connection, so offline
documentation is absolutely essential. (You hear that Microsoft? Not
only do I avoid coding against Win32 because it’s badly designed, but
even more so because you don’t offer offline documentation anymore!
The friction to API reference your documentation is enormous.)
I avoided the official x86 documentation for awhile, thinking it would
be too opaque, at least until I became more accustomed to the
instruction set. But really, it’s not bad! With a handle on the
basics, I would encourage anyone to dive into either Intel’s or AMD’s
manuals. The reason there’s not much online in HTML form is
because these manuals are nearly everything you need.
I chose Intel’s manuals for x86-lookup because I’m more familiar with
it, it’s more popular, it’s (slightly) easier to parse, it’s offered
as a single PDF, and it’s more complete. The regular expression for
finding instructions is tuned for Intel’s manual and it won’t work
with AMD’s manuals.
For a couple months prior to writing x86-lookup, I had a couple of
scratch functions to very roughly accomplish the same thing. The
tipping point for formalizing it was that last month I wrote my own
x86 assembler. A single mnemonic often has a dozen or more different
opcodes depending on the instruction’s operands, and there are often
several ways to encode the same operation. I was frequently looking up
opcodes, and navigating the PDF quickly became a real chore. I only
needed about 80 different opcodes, so I was just adding them to the
assembler’s internal table manually as needed.
How does it work?
Say you want to look up the instruction RDRAND.
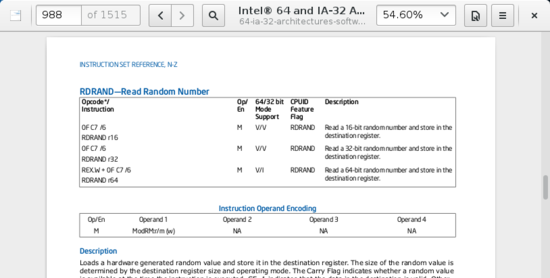
Initially Emacs has no idea what page this is on, so the first step is
to build an index mapping mnemonics to pages. x86-lookup runs the
pdftotext command line program on the PDF and loads the result into a
temporary buffer.
The killer feature of pdftotext is that it emits FORM FEED (U+0012)
characters between pages. Think of these as page breaks. By counting
form feed characters, x86-lookup can track the page for any part of
the document. In fact, Emacs is already set up to do this with its
forward-page and backward-page commands. So to build the index,
x86-lookup steps forward page-by-page looking for mnemonics, keeping
note of the page. Since this process typically takes about 10 seconds,
the index is cached in a file (see x86-lookup-cache-directory) for
future use. It only needs to happen once for a particular manual on a
particular computer.
The mnemonic listing is slightly incomplete, so x86-lookup expands
certain mnemonics into the familiar set. For example, all the
conditional jumps are listed under “Jcc,” but this is probably not
what you’d expect to look up. I compared x86-lookup’s mnemonic listing
against NASM/nasm-mode’s mnemonics to ensure everything was accounted
for. Both packages benefited from this process.
Once the index is built, pdftotext is no longer needed. If you’re
desperate and don’t have this program available, you can borrow the
index file from another computer. But you’re on your own for figuring
that out!
So to look up RDRAND, x86-lookup checks the index for the page number
and invokes a PDF reader on that page. This is where not all PDF
readers are created equal. There’s no convention for opening a PDF to
a particular page and each PDF reader differs. Some don’t even support
it. To deal with this, x86-lookup has a function specialized for
different PDF readers. Similar to browse-url-browser-function,
x86-lookup has x86-lookup-browse-pdf-function.
By default it tries to open the PDF for viewing within Emacs (did you
know Emacs is a PDF viewer?), falling back to on options if the
feature is unavailable. I welcome pull requests for any PDF readers
not yet supported by x86-lookup. Perhaps this functionality deserves
its own package.
That’s it! It’s a simple feature that has already saved me a lot of
time. If you’re ever programming in x86 assembly, give x86-lookup a
spin.