nullprogram.com/blog/2014/01/04/
Byte-code compilation is an underdocumented — and in the case of the
recent lexical binding updates, undocumented — part of Emacs. Most
users know that Elisp is usually compiled into a byte-code saved to
.elc files, and that byte-code loads and runs faster than uncompiled
Elisp. That’s all users really need to know, and the GNU Emacs Lisp
Reference Manual specifically discourages poking around too much.
People do not write byte-code; that job is left to the byte
compiler. But we provide a disassembler to satisfy a cat-like
curiosity.
Screw that! What if I want to handcraft some byte-code myself? :-) The
purpose of this article is to introduce the internals of Elisp
byte-code interpreter. I will explain how it works, why lexically
scoped code is faster, and demonstrate writing some byte-code by hand.
The Humble Stack Machine
The byte-code interpreter is a simple stack machine. The stack holds
arbitrary lisp objects. The interpreter is backwards compatible but
not forwards compatible (old versions can’t run new byte-code). Each
instruction is between 1 and 3 bytes. The first byte is the opcode and
the second and third bytes are either a single operand or a single
intermediate value. Some operands are packed into the opcode byte.
As of this writing (Emacs 24.3) there are 142 opcodes, 6 of which have
been declared obsolete. Most opcodes refer to commonly used built-in
functions for fast access. (Looking at the selection, Elisp really is
geared towards text!) Considering packed operands, there are up to 27
potential opcodes unused, reserved for the future.
- opcodes 48 - 55
- opcode 97
- opcode 128
- opcodes 169 - 174
- opcodes 180 - 181
- opcodes 183 - 191
The easiest place to access the opcode listing is in
bytecomp.el. Beware that some of the opcode comments are
currently out of date.
Segmentation Fault Warning
Byte-code does not offer the same safety as normal Elisp. Bad
byte-code can, and will, cause Emacs to crash. You can try out for
yourself right now,
emacs -batch -Q --eval '(print (#[0 "\300\207" [] 0]))'
Or evaluate the code manually in a buffer (save everything first!),
This segfault, caused by referencing beyond the end of the constants
vector, is not an Emacs bug. Doing a boundary test would slow down
the byte-code interpreter. Not performing this test at run-time is a
practical engineering decision. The Emacs developers have instead
chosen to rely on valid byte-code output from the compiler, making a
disclaimer to anyone wanting to write their own byte-code,
You should not try to come up with the elements for a byte-code
function yourself, because if they are inconsistent, Emacs may crash
when you call the function. Always leave it to the byte compiler to
create these objects; it makes the elements consistent (we hope).
You’ve been warned. Now it’s time to start playing with firecrackers.
The Byte-code Object
A byte-code object is functionally equivalent to a normal Elisp vector
except that it can be evaluated as a function. Elements are accessed
in constant time, the syntax is similar to vector syntax ([...] vs.
#[...]), and it can be of any length, though valid functions must
have at least 4 elements.
There are two ways to create a byte-code object: using a byte-code
object literal or with make-byte-code.
Like vector literals, byte-code literals don’t need to be
quoted.
(make-byte-code 0 "" [] 0)
;; => #[0 "" [] 0]
#[1 2 3 4]
;; => #[1 2 3 4]
(#[0 "" [] 0])
;; error: Invalid byte opcode
The elements of an object literal are:
- Function parameter (lambda) list
- Unibyte string of byte-code
- Constants vector
- Maximum stack usage
- Docstring (optional, nil for none)
- Interactive specification (optional)
Parameter List
The parameter list takes on two different forms depending on if the
function is lexically or dynamically scoped. If the function is
dynamically scoped, the argument list is exactly what appears in lisp
code.
(byte-compile (lambda (a b &optional c)))
;; => #[(a b &optional c) "\300\207" [nil] 1]
There’s really no shorter way to represent the parameter list because
preserving the argument names is critical. Remember that, in dynamic
scope, while the function body is being evaluated these variables are
globally bound (eww!) to the function’s arguments.
When the function is lexically scoped, the parameter list is packed
into an Elisp integer, indicating the counts of the different kinds of
parameters: required, &optional, and &rest.
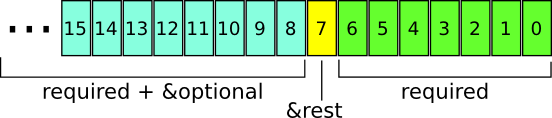
The least significant 7 bits indicate the number of required
arguments. Notice that this limits compiled, lexically-scoped
functions to 127 required arguments. The 8th bit is the number of
&rest arguments (up to 1). The remaining bits indicate the total
number of optional and required arguments (not counting &rest). It’s
really easy to parse these in your head when viewed as hexadecimal
because each portion almost always fits inside its own “digit.”
(byte-compile-make-args-desc '())
;; => #x000 (0 args, 0 rest, 0 required)
(byte-compile-make-args-desc '(a b))
;; => #x202 (2 args, 0 rest, 2 required)
(byte-compile-make-args-desc '(a b &optional c))
;; => #x302 (3 args, 0 rest, 2 required)
(byte-compile-make-args-desc '(a b &optional c &rest d))
;; => #x382 (3 args, 1 rest, 2 required)
The names of the arguments don’t matter in lexical scope: they’re
purely positional. This tighter argument specification is one of the
reasons lexical scope is faster: the byte-code interpreter doesn’t
need to parse the entire lambda list and assign all of the variables
on each function invocation.
Unibyte String Byte-code
The second element is a unibyte string — it strictly holds octets and
is not to be interpreted as any sort of Unicode encoding. These
strings should be created with unibyte-string because string may
return a multibyte string. To disambiguate the string type to the lisp
reader when higher values are present (> 127), the strings are printed
in an escaped octal notation, keeping the string literal inside the
ASCII character set.
(unibyte-string 100 200 250)
;; => "d\310\372"
It’s unusual to see a byte-code string that doesn’t end with 135
(#o207, byte-return). Perhaps this should have been implicit? I’ll
talk more about the byte-code below.
Constants Vector
The byte-code has very limited operands. Most operands are only a few
bits, some fill an entire byte, and occasionally two bytes. The meat
of the function that holds all the constants, function symbols, and
variables symbols is the constants vector. It’s a normal Elisp vector
and can be created with vector or a vector literal. Operands
reference either this vector or they index into the stack itself.
(byte-compile (lambda (a b) (my-func b a)))
;; => #[(a b) "\302\134\011\042\207" [b a my-func] 3]
Note that the constants vector lists the variable symbols as well as
the external function symbol. If this was a lexically scoped function
the constants vector wouldn’t have the variables listed, being only
[my-func].
Maximum Stack Usage
This is the maximum stack space used by this byte-code. This value can
be derived from the byte-code itself, but it’s pre-computed so that
the byte-code interpreter can quickly check for stack overflow.
Under-reporting this value is probably another way to crash Emacs.
Docstring
The simplest component and completely optional. It’s either the
docstring itself, or if the docstring is especially large it’s a cons
cell indicating a compiled .elc and a position for lazy access. Only
one position, the start, is needed because the lisp reader is used to
load it and it knows how to recognize the end.
Interactive Specification
If this element is present and non-nil then the function is an
interactive function. It holds the exactly contents of interactive
in the uncompiled function definition.
(byte-compile (lambda (n) (interactive "nNumber: ") n))
;; => #[(n) "\010\207" [n] 1 nil "nNumber: "]
(byte-compile (lambda (n) (interactive (list (read))) n))
;; => #[(n) "\010\207" [n] 1 nil (list (read))]
The interactive expression is always interpreted, never byte-compiled.
This is usually fine because, by definition, this code is going to be
waiting on user input. However, it slows down keyboard macro playback.
Opcodes
The bulk of the established opcode bytes is for variable, stack, and
constant access opcodes, most of which use packed operands.
- 0 - 7 : (
stack-ref) stack reference
- 8 - 15 : (
varref) variable reference (from constants vector)
- 16 - 23 : (
varset) variable set (from constants vector)
- 24 - 31 : (
varbind) variable binding (from constants vector)
- 32 - 39 : (
call) function call (immediate = number of arguments)
- 40 - 47 : (
unbind) variable unbinding (from constants vector)
- 129, 192-255 : (
constant) direct constants vector access
Except for the last item, each kind of instruction comes in sets of 8.
The nth such instruction means access the nth thing. For example, the
instruction “2” copies the third stack item to the top of the stack.
An instruction of “9” pushes onto the stack the value of the
variable named by the second element listed in the constants vector.
However, the 7th and 8th such instructions in each set take an operand
byte or two. The 7th instruction takes a 1-byte operand and the 8th
takes a 2-byte operand. A 2-byte operand is written in little-endian
byte-order regardless of the host platform.
For example, let’s manually craft an instruction that returns the
value of the global variable foo. Each opcode has a named constant
of byte-X so we don’t have to worry about their actual byte-code
number.
(require 'bytecomp) ; named opcodes
(defvar foo "hello")
(defalias 'get-foo
(make-byte-code
#x000 ; no arguments
(unibyte-string
(+ 0 byte-varref) ; ref variable under first constant
byte-return) ; pop and return
[foo] ; constants
1)) ; only using 1 stack space
(get-foo)
;; => "hello"
Ta-da! That’s a handcrafted byte-code function. I left a “+ 0” in
there so that I can change the offset. This function has the exact
same behavior, it’s just less optimal,
(defalias 'get-foo
(make-byte-code
#x000
(unibyte-string
(+ 3 byte-varref) ; 4th form of varref
byte-return)
[nil nil nil foo]
1))
If foo was the 10th constant, we would need to use the 1-byte
operand version. Again, the same behavior, just less optimal.
(defalias 'get-foo
(make-byte-code
#x000
(unibyte-string
(+ 6 byte-varref) ; 7th form of varref
9 ; operand, (constant index 9)
byte-return)
[nil nil nil nil nil nil nil nil nil foo]
1))
Dynamically-scoped code makes heavy use of varref but
lexically-scoped code rarely uses it (global variables only), instead
relying heavily on stack-ref, which is faster. This is where the
different calling conventions come into play.
Calling Convention
Each kind of scope gets its own calling convention. Here we finally
get to glimpse some of the really great work by Stefan Monnier
updating the compiler for lexical scope.
Dynamic Scope Calling Convention
Remembering back to the parameter list element of the byte-code
object, dynamically scoped functions keep track of all its argument
names. Before executing a function the interpreter examines the lambda
list and binds (varbind) every variable globally to an argument.
If the caller was byte-compiled, each argument started on the stack,
was popped and bound to a variable, and, to be accessed by the
function, will be pushed back right onto the stack (varref). There’s
a lot of argument indirection for each function call.
Lexical Scope Calling Convention
With lexical scope, the argument names are not actually bound for the
evaluation byte-code. The names are completely gone because the
compiler has converted local variables into stack offsets.
When calling a lexically-scoped function, the byte-code interpreter
examines the integer parameter descriptor. It checks to make sure the
appropriate number of arguments have been provided, and for each
unprovided &optional argument it pushes a nil onto the stack. If the
function has a &rest parameter, any extra arguments are popped off
into a list and that list is pushed onto the stack.
From here the function can access its arguments directly on the stack
without any named variable misdirection. It can even consume them
directly.
;; -*- lexical-binding: t -*-
(defun foo (x) x)
(symbol-function #'foo)
;; => #[#x101 "\207" [] 2]
The byte-code for foo is a single instruction: return. The
function’s argument is already on the stack so it doesn’t have to do
anything. Strangely the maximum stack usage element is wrong here (2),
but it won’t cause a crash.
;; (As of this writing `byte-compile' always uses dynamic scope.)
(byte-compile 'foo)
;; => #[(x) "\010\207" [x] 1]
It takes longer to set up (x is implicitly bound), it has to make an
explicit variable dereference (varref), then it has to clean up by
unbinding x (implicit unbind). It’s no wonder lexical scope is
faster!
Note that there’s also a disassemble function for examining
byte-code, but it only reveals part of the story.
(disassemble #'foo)
;; byte code:
;; args: (x)
;; 0 varref x
;; 1 return
The Elisp byte-compiler has an intermediate language called lapcode
(“Lisp Assembly Program”), which is much easier to optimize than
byte-code. It’s basically an assembly language built out of
s-expressions. Opcodes are referenced by name and operands, including
packed operands, are handled whole. Each instruction is a cons cell,
(opcode . operand), and a program is a list of these.
Let’s rewrite our last get-foo using lapcode.
(defalias 'get-foo
(make-byte-code
#x000
(byte-compile-lapcode
'((byte-varref . 9)
(byte-return)))
[nil nil nil nil nil nil nil nil nil foo]
1))
We didn’t have to worry about which form of varref we were using or
even how to encode a 2-byte operand. The lapcode “assembler” took care
of that detail.
Project Ideas?
The Emacs byte-code compiler and interpreter are fascinating. Having
spent time studying them I’m really tempted to build a project on top
of it all. Perhaps implementing a programming language that targets
the byte-code interpreter, improving compiler optimization, or, for a
really big project, JIT compiling Emacs byte-code.
People can write byte-code!